

Around 7am AEST, most Google users around the world who logged in to Google services like Gmail, Google+, Calendar and Documents were unable to access them for approximately 25 minutes.
“For about 10% of users, the problem persisted for as much as 30 minutes longer,” said Google’s engineering VP Ben Treynor in a blog post. “Whether the effect was brief or lasted the better part of an hour, please accept our apologies—we strive to make all of Google’s services available and fast for you, all the time, and we missed the mark today.”
Treynor said the issue was quickly resolved. “We’re now focused on correcting the bug that caused the outage, as well as putting more checks and monitors in place to ensure that this kind of problem doesn’t happen again.”
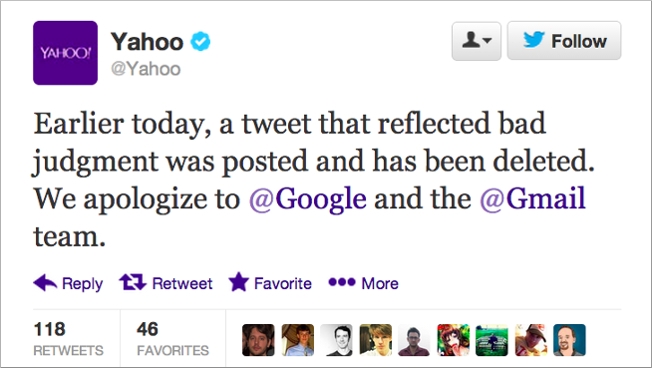
Google rival Yahoo briefly posted a screen shot of Google’s error message on Twitter. It then deleted it and apologised for its ‘bad judgement.’ People who live in glass houses …
Treynor’s explanation for the outage: At 10:55 a.m. PST this morning [Friday], an internal system that generates configurations—essentially, information that tells other systems how to behave—encountered a software bug and generated an incorrect configuration.
The incorrect configuration was sent to live services over the next 15 minutes, caused users’ requests for their data to be ignored, and those services, in turn, generated errors. Users began seeing these errors on affected services at 11:02 a.m., and at that time our internal monitoring alerted Google’s Site Reliability Team.
Engineers were still debugging 12 minutes later when the same system, having automatically cleared the original error, generated a new correct configuration at 11:14 a.m. and began sending it; errors subsided rapidly starting at this time. By 11:30 a.m. the correct configuration was live everywhere and almost all users’ service was restored.
With services once again working normally, our work is now focused on (a) removing the source of failure that caused today’s outage, and (b) speeding up recovery when a problem does occur. We'll be taking the following steps in the next few days:
- Correcting the bug in the configuration generator to prevent recurrence, and auditing all other critical configuration generation systems to ensure they do not contain a similar bug.
- Adding additional input validation checks for configurations, so that a bad configuration generated in the future will not result in service disruption.
- Adding additional targeted monitoring to more quickly detect and diagnose the cause of service failure.